Bagaimana Jika Kita Dapat Mencari Kata Kunci Apapun dari Video YouTube Manapun Melalui Captionnya?
Lompat ke artikel utama.
Demo Pencarian Teks Tertutup YouTube
"Judul Video" olehNama Kanal
Catatan:
- Hanya video YouTube yang memiliki subtitle berbahasa Inggris yang didukung.
- Tidak dapat digunakan pada video YouTube berhak cipta, seperti musik video.
- Setiap pranala YouTube memerlukan waktu yang lebih lama saat pertama kali dicari karena temboloknya (cache) belum tersedia.
- Untuk mengurangi penggunaan data, fitur demo otomatis hanya berjalan jika bagian demo ini terlihat di layar peramban (browser) teman-teman.
Tidak sedang mencari kata kunci apapun, coba masukkan sebuah kata kunci.
Timer: 15s
0 hasil pencarian ditemukan. Saat ini berada pada halaman ke-0
Rangkuman
Tahun lalu saya mendapatkan ide untuk membuat suatu aplikasi web yang dapat mencari kata kunci dari perkataan orang di video YouTube. Ide tersebut muncul ketika saya sedang menonton web.dev Live. Aplikasi web tersebut tidak menggunakan teknologi yang canggih dan terkini, hanya melakukan pencarian dari caption-nya.
Ketika kita mengaktifkan fitur caption pada YouTube, halaman YouTube akan melakukan request data dari API. Responnya berupa objek JSON yang dapat kita ubah menjadi format lain, seperti WebVTT. Sayangnya, API tersebut dilengkapi dengan beberapa parameter yang memiliki identitas unik dan waktu kadaluarsa.
Karena hal tersebut, kita tidak bisa mengakses pranala API tersebut dengan sering. Untungnya, setiap video YouTube memiliki identitas unik di pranala nya. Tidak hanya pada halaman YouTube biasa, tetapi juga pada versi embedded-nya. Kita dapat menggunakan puppeteer untuk mengakses halaman embedded dan meng-intercept request-nya untuk mendapatkan pranala API caption tersebut.
Kemudian kita dapat memproses data caption menggunakan beberapa paket NPM bersumber terbuka dan mengubahnya menjadi REST API kita sendiri. API ini hanya membutuhkan pranala video YouTube dan sebuah kata kunci. Kita juga menggunakan Vercel sebagai tempat hosting layanan API yang gratis.
Teman-teman dapat mempelajari lebih lanjut dokumentasi API-nya pada API Cari Teks Video dan daftar proyek-proyek keren yang telah menggunakan API ini pada Awesome Cari Teks Video. Teman-teman juga dapat membaca artikel ini lebih lanjut untuk mempelajari bagaimana implementasinya.
Awal Mula
Pada tanggal 30 Juni sampai 2 Juli 2020 tahun kemarin, tim Chrome Developer Advocate mengadapak acara yang sangat spektakuler untuk pengembang web. Acara tersebut bernama web.dev Live.
Saya sedang melihat acara tersebut hingga suatu saat salah satu Chrome Developer Advocate, Sam Dutton membagikan sebuah pranala di kotak chat. Saya klik pranala tersebut dan ternyata link tersebut berisi aplikasi untuk mencari, menjelajahi caption dari video acara web.dev Live.
Aplikasi tersebut bernama Search web.dev LIVE. Awalnya saya terkesima karena kita dapat mencari sesuatu dari sebuah video walaupun hanya melalui caption-nya. Saya melihat pranala GitHub pada bagian footer untuk melihat teknologi dibalik aplikasi web tersebut.
Ternyata aplikasi web tersebut tidak menggunakan teknologi yang benar-benar terkini. Tidak juga menggunakan kecerdasan buatan atau algoritma yang kompleks. Hanya JavaScript sederhana, beberapa paket NPM dan berkas caption. Hal yang sangat menarik bagi saya.
Saya rasa kekurangan dari Search web.dev Live adalah ia hanya dapat mencari dari video acara web.dev Live. Omong-omong, video acara web.dev Live ditayangkan di YouTube. Dan berkas caption-nya disimpan di repositori GitHubnya sendiri.
“Bagaimana jika kita dapat melakukan pencarian tersebut, tetapi untuk semua video di YouTube”, pikir saya. Berdasarkan asumsi saya, algoritmanya mungkin seperti berikut:
- JavaScript mengambil kata kunci dari input.
- Cari kata kunci tersebut dari semua berkas caption yang ada.
- Soroti hasil pencariannya.
Sebenarnya mudah bukan? Dan ternyata tidak membutuhkan waktu lama hingga saya menemukan bahwa kita dapat mendapatkan caption YouTube dari sebuah pranala tertentu.
Pertama-tama, kita harus membuka sebuah video YouTube kemudian mengaktifkan fitur caption-nya.
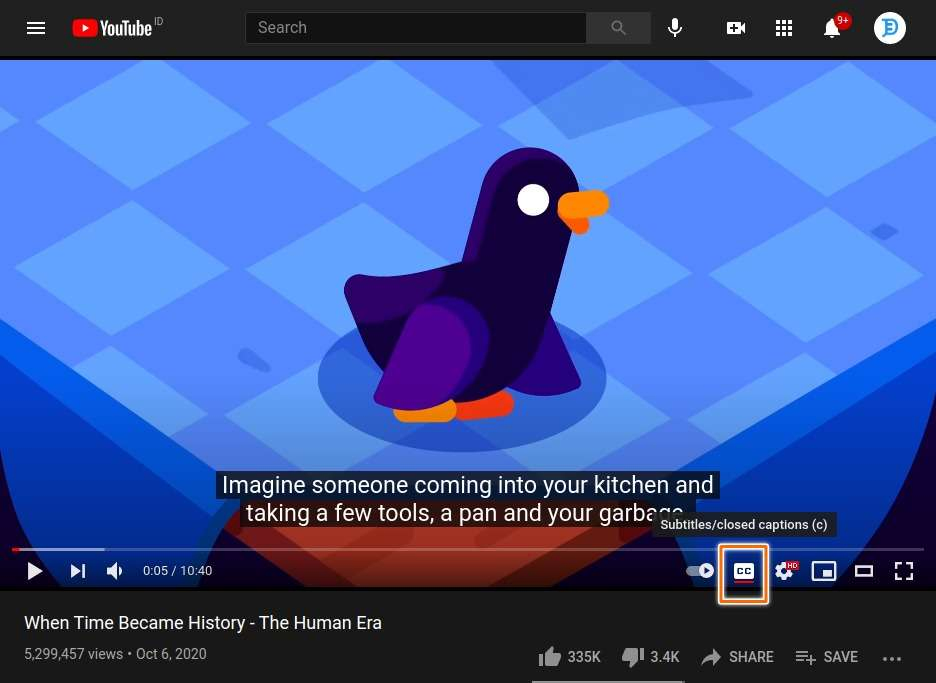
Setelah itu, YouTube akan mengakses sebuah API. Respon dari API tersebut adalah caption dari video yang kita tonton.
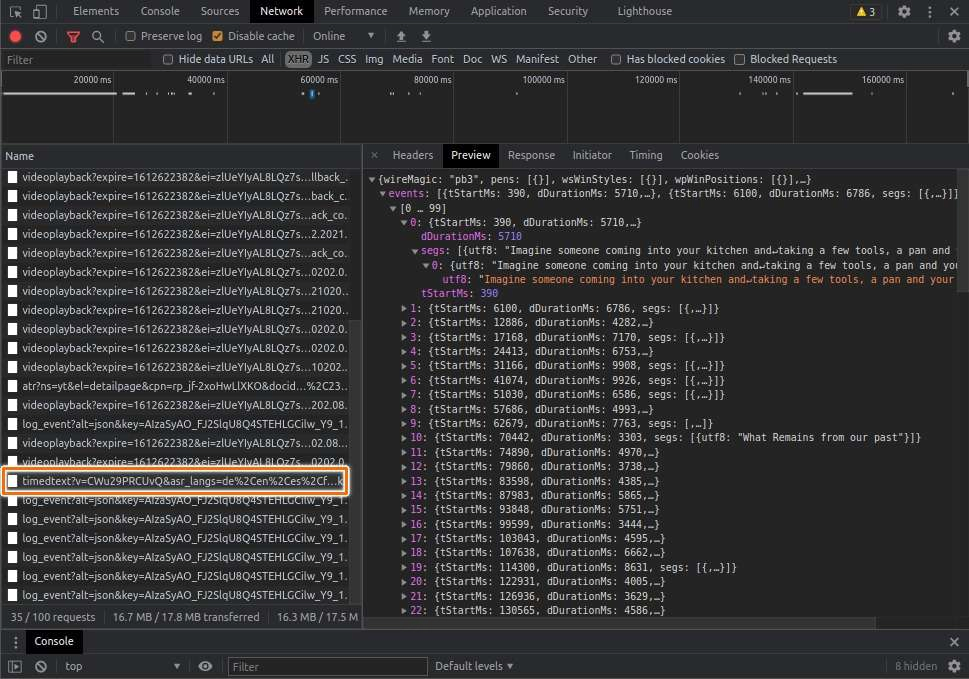
Berikut contoh pranala API-nya:
const const ccUrl: "https://www.youtube.com/api/timedtext?v=CWu29PRCUvQ&asr_langs=de%2Cen%2Ces%2Cfr%2Cit%2Cja%2Cko%2Cnl%2Cpt%2Cru&caps=asr&exp=xftt&xorp=true&xoaf=5&hl=en&ip=0.0.0.0&ipbits=0&expire=1612625982&sparams=ip%2Cipbits%2Cexpire%2Cv%2Casr_langs%2Ccaps%2Cexp%2Cxorp%2Cxoaf&signature=CC705091625358E3A3883C981A21BFC4F6E35569.77DAB826C17A839CEE703DB894D73D8AECCA0AE2&key=yt8&lang=en-GB&fmt=json3&xorb=2&xobt=3&xovt=3"ccUrl = 'https://www.youtube.com/api/timedtext?v=CWu29PRCUvQ&asr_langs=de%2Cen%2Ces%2Cfr%2Cit%2Cja%2Cko%2Cnl%2Cpt%2Cru&caps=asr&exp=xftt&xorp=true&xoaf=5&hl=en&ip=0.0.0.0&ipbits=0&expire=1612625982&sparams=ip%2Cipbits%2Cexpire%2Cv%2Casr_langs%2Ccaps%2Cexp%2Cxorp%2Cxoaf&signature=CC705091625358E3A3883C981A21BFC4F6E35569.77DAB826C17A839CEE703DB894D73D8AECCA0AE2&key=yt8&lang=en-GB&fmt=json3&xorb=2&xobt=3&xovt=3'Mari kita cermati parameter kueri yang terdapat pada pranala tersebut:
{
"v": "CWu29PRCUvQ",
"asr_langs": "de,en,es,fr,it,ja,ko,nl,pt,ru",
"caps": "asr",
"exp": "xftt",
"xorp": "true",
"xoaf": "5",
"hl": "en",
"ip": "0.0.0.0",
"ipbits": "0",
"expire": "1612625982",
"sparams": "ip,ipbits,expire,v,asr_langs,caps,exp,xorp,xoaf",
"signature": "CC705091625358E3A3883C981A21BFC4F6E35569.77DAB826C17A839CEE703DB894D73D8AECCA0AE2",
"key": "yt8",
"lang": "en-GB",
"fmt": "json3",
"xorb": "2",
"xobt": "3",
"xovt": "3"
}Kita dapat memahami beberapa pasang key-value:
vberisi identitas unik video YouTube.hlkependekan dari host language. Cukup umum bagi layanan API Google menggunakan key ini. Fungsinya mendefinisikan sesuatu yang berhubungan dengan pengaturan bahasa.expirekapan request API akan kadaluarsa. Nilainya berformat detik.signatureidentitas acak dari setiap request. Menurut saya, nilai dari key ini mendefinisikan request mana yang berhak diproses. Tanggal kadaluarsa nampaknya juga memiliki koneksi dengan identitas ini. Saya mencoba menghilangkan parameter ini ketika mengakses API-nya tetapi malah mendapatkan respon gagal.fmtmendefinisikan format respon. Secara default, respon API terformat sebagaijson3. Anggapan saya nilai tersebut dapat diubah. Saya mencoba format caption lain, sepertivttdan ternyata bekerja.
Sebenarnya masih terdapat beberapa paasng key-value lainnya, tetapi yang saya sebutkan di atas merupakan yang paling penting.
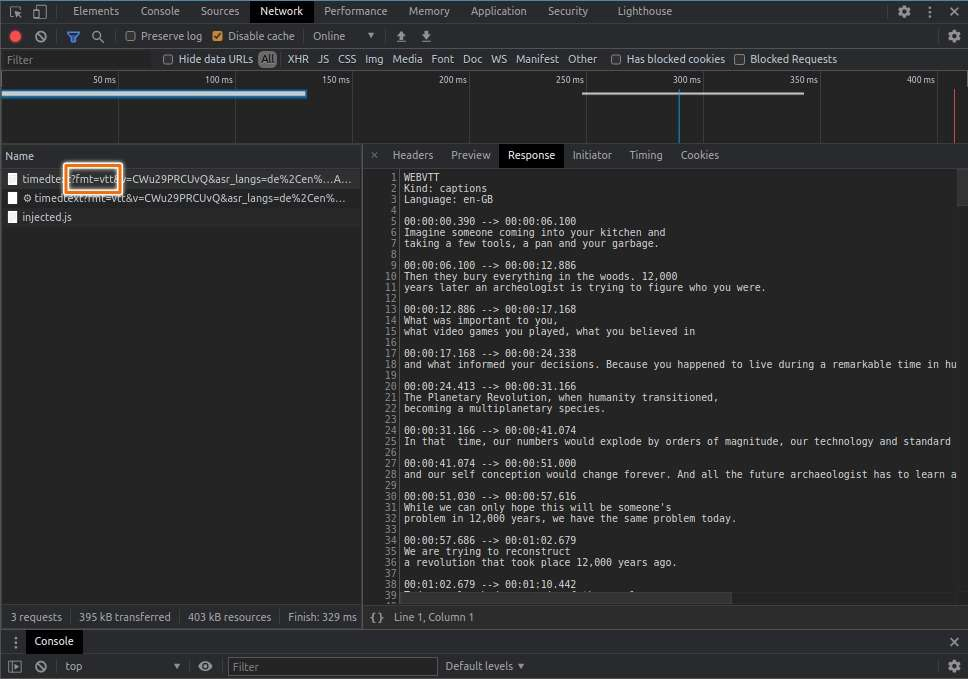
Yeaye! Saya rasa kita dapat menggunakan pranala API tersebut untuk membangun aplikasi web pencari kata kunci dari sebuah video YouTube.
Tetapi sebelum kita melanjutkan pembahasan, mari kita melihat terlebih dahulu isi dari format WebVTT:
WEBVTT
Kind: captions
Language: en
00:00:00.357 --> 00:00:01.822
- [Narrator] There is
a growing feeling today
00:00:01.822 --> 00:00:04.699
that something is wrong with
our system of education.WebVTT hanyalah sebuah teks biasa dengan format konten tertentu. Secara umum, WebVTT terdiri dari 2 bagian, header dan cue.
WEBVTT
Kind: captions
Language: enHeader berisi metadata mengenai caption, seperti bahasa yang digunakan atau pembuat caption-nya.
00:00:00.357 --> 00:00:01.822
- [Narrator] There is
a growing feeling today
00:00:01.822 --> 00:00:04.699
that something is wrong with
our system of education.Cue dapat dibagi menjadi 3 bagian, waktu mulai, waktu berakhir dan teks. Teks merupakan caption yang akan ditampilkan saat video diputar. Waktu mulai menunjukkan kapan suatu bagian teks akan ditampilkan sedangkan waktu berakhir menunjukkan kapan dihilangkan.
Bahan Baku
Berikut beberapa paket NPM utama yang dapat kita gunakan untuk membuat API:
- @vercel/node, kita akan mengunggah kode kita ke Vercel, sehingga kita membutuhkan paket NPM ini untuk menjalankan API kita di sana.
- chrome-aws-lambda, Vercel Serverless Function di balik layar berjalan di atas AWS Lambda. AWS Lambda memiliki batas pada seberapa besar ukuran fungsi yang dijalankan. Kalau tidak salah, ukuran maksimum sekitar 50MB dan ukuran maksimum ketika diekstrak (unzipped) sekitar 250MB. Untuk mengakomodasi batasan ini, kita tidak dapat menggunakan puppeteer yang biasa. Karena puppeteer yang biasa akan mengunduh berkas Chrome secara penuh. Sebagai gantinya, kita akan menggunakan puppeteer-core dan paket ini sebagai pendampingnya. Paket ini akan memasang versi chrome yang lebih kecil ukurannya karena terkompresi menggunakan algoritma Brotli.
- flexsearch, kita akan membuat API untuk pencarian, sehingga kita membutuhkan mekanisme pencarian supaya efektif. Meskipun kita dapat menggunakan fungsi
Array.prototype.filterbawaan JavaScript, menurut pendapat saya akan lebih baik jika kita dapat meningkatkan peforma pencarian menggunakan perpustakaan pihak ke-3. Aplikasi web Searh web.dev Live juga menggunakan paket NPM ini. - get-urls, paket NPM ini sangat berguna untuk mengekstrak metadata pranala dari sebuah string. Secara spesifik untuk mendapatkan pranala logo.
- isomorphic-fetch, kita akan menggunakan paket ini untuk mengambil data caption dari REST API YouTube.
- joi, paket NPM ini berguna untuk validasi objek. Dia akan memastikan semua data sesuai dengan format yang telah ditentukan.
- pino-logflare, log merupakan bagian yang cukup krusial dalam teknologi. Kita dapat menggunakannya untuk mencari dan memperbaiki bug. Namun, Vercel memiliki aturan yang berbeda dalam hal penyimpanan log. Singkatnya, cukup susah untuk mendapatkan informasi penting dari log karena batasan tersebut. Untungnya, Vercel juga menyediakan fitur bernama Log Drain. Sederhananya, Vercel tidak akan menyimpan log di server-nya, melainkan pada layanan lain yang dikhususkan untuk menyimpan log aplikasi. Salah satunya adalah Logflare. Paket ini mengintegrasikan logger express bernama Pino dengan Logflare.
- puppeteer-core, puppeteer merupakan headless chrome, kita membutuhkannya untuk membuka halaman YouTube.
- string-strip-html, terkadang caption berisi kode HTML. Kita membutuhkan paket NPM ini untuk menghilangkannya.
- caption, kita mendapatkan data caption dari YouTube API dalam format WebVTT. Paket NPM ini berguna untuk mem-parsing dan mengubah format tersebut menjadi objek JavaScript.
- typescript, JavaScript dengan tipe anotasi.
Untuk melihat lebih banyak paket NPM yang digunakan, teman-teman dapat melihatnya di berkas package.json pada repositori berikut, Cari Teks Video API.
Modul
Kita telah mempunyai semua bahan bakunya. Sekarang kita akan membuat API dengan 2 endpoint, yang pertama adalah / dan yang kedua adalah /search. Endpoint indeks hanya kita gunakan untuk mendapatkan data caption dari YouTube. Sedangkan endpoint search untuk pencarian. Pada artikel kali ini, kita akan lebih banyak membahas mengenai endpoint pencarian.
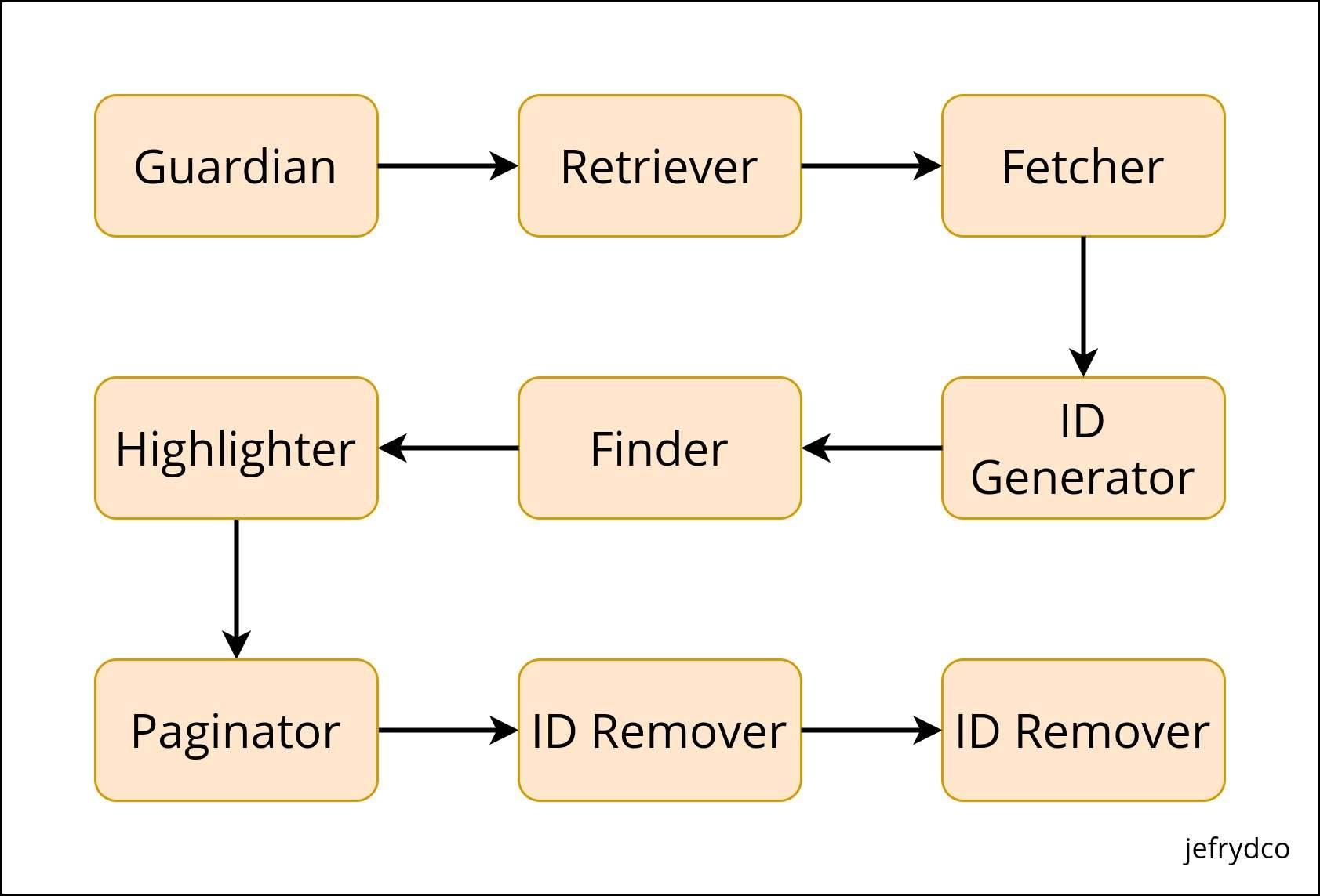
Berdasarkan diagram di atas, kita dapat membagi REST API yang akan kita buat menjadi 8 modul yang lebih kecil.
Guardian
Sesuai dengan namanya, Guardian yang berarti penjaga. Fungsi dari modul ini adalah memastikan parameter dan data yang didapat sesuai. Kita akan menggunakan Joi sebagai Guardian kita.
import import joijoi from 'joi'
const const indexQuery: anyindexQuery = import joijoi.object({
url: anyurl: import joijoi.string().required(),
page: anypage: import joijoi.string().optional(),
size: anysize: import joijoi.string().optional(),
paginated: anypaginated: import joijoi.number().integer().allow(0, 1).optional()
})
const const searchQuery: anysearchQuery = const indexQuery: anyindexQuery.keys({
q: anyq: import joijoi.string().min(3).required(),
marked: anymarked: import joijoi.number().integer().allow(0, 1).optional()
})Mengikuti endpoint REST API yang kita buat, ada 2 jenis parameter kueri. Yang pertama untuk indeks dan yang kedua untuk pencarian. Parameter kueri untuk pencarian meng-extend indeks.
Jika teman-teman ingin mengetahui fungsi setiap parameter kueri, teman-teman dapat mempelajarinya di dokumentasi Cari Teks Video API - Request.
Retriever
Retriever berguna untuk mendapatkan data dari parameter kueri. Seperti yang kita lakukan pada Guardian, kita juga harus membagi retriever menjadi 2 jenis fungsi, indeks dan pencarian.
Untuk url, kita memasukkan pranala YouTube secara langsung sebagai parameter kueri. Tetapi jika kita membuka halaman YouTube secara umum, akan membutuhkan waktu yang lebih lama. Sehingga kita menggunakan versi embedded-nya. Oleh karena itu kita harus mengubah pranala tersebut menjadi versi embedded-nya.
Yang kita butuhkan hanyalah identitas video YouTube. Kita dapat menggunakan Regular Expression atau pada umumnya disingkat sebagai RegEx untuk menyelesaikan permasalahan tersebut. Berikut RegEx yang akan kita gunakan:
const const youtubeUrl: "https://www.youtube.com/watch?v=okpg-lVWLbE"youtubeUrl = 'https://www.youtube.com/watch?v=okpg-lVWLbE'
const const result: RegExpExecArray | nullresult = /(?:youtube\.com\/(?:[^\/]+\/.+\/|(?:v|e(?:mbed)?)\/|.*[?&]v=)|youtu\.be\/)([^"&?\/\s]{11})/gi
.RegExp.exec(string: string): RegExpExecArray | nullExecutes a search on a string using a regular expression pattern, and returns an array containing the results of that search.exec(const youtubeUrl: "https://www.youtube.com/watch?v=okpg-lVWLbE"youtubeUrl)
let let id: stringid = ''
if (var Array: ArrayConstructorArray.ArrayConstructor.isArray(arg: any): arg is any[]isArray(const result: RegExpExecArray | nullresult) && const result: RegExpExecArrayresult.Array<string>.length: numberGets or sets the length of the array. This is a number one higher than the highest index in the array.length > 0) {
let id: stringid = const result: RegExpExecArrayresult[1]
}RegEx yang cukup panjang tetapi bekerja dengan baik. Saya mendapatkannya dari utas StackOverflow berikut, Regular Expression untuk Identitas YouTube.
Setelah kita mendapatkan identitas video tersebut, kita dapat menggabungkannya dengan pranala embedded YouTube.
// previous code
const const youtubeEmbedUrl: stringyoutubeEmbedUrl = `https://www.youtube.com/embed/${const id: stringid}?hl=en&cc_lang_pref=en&cc_load_policy=1&autoplay=1`Kita juga menambahkan beberapa parameter pada pranala tersebut.
hl, sama sepertihlyang terdapat pada API caption YouTube yang telah kita diskusikan di atas.hlmerupakan kependekan dari host language yang berfungsi untuk mengatur bahasa antarmuka pemutar video.cc_lang_pref, parameter ini mengatur bahasa default untuk menampilkan caption.cc_load_policy, berfungsi untuk mengaktifkan caption secara otomatis jika nilainya1.autoplay, memainkan video secara otomatis ketika termuat jika nilainya1.
Fetcher
Modul ini merupakan bagian yang memerlukan waktu terbanyak untuk dibuat. Fetcher berisi beberapa submodul untuk mendapatkan API caption YouTube, fetcher indeks dan fetcher pencarian.
YouTube Closed Captions Fetcher
Fetcher ini sebenarnya digunakan pada endpoint indeks. Tetapi untuk memahami bagaimana kita mendapatkan data caption, kita harus membahasnya.
Kita telah memahami algoritma untuk mendapatkan pranala API caption YouTube. Kita harus mengubahnya menjadi kode yang nyata. Kita menggunakan puppeteer dan Chrome AWS Lambda untuk melakukannya. Mari kita lihat potongan kode berikut:
import import chromechrome from 'chrome-aws-lambda'
import import puppeteerpuppeteer from 'puppeteer-core'
async function function getYoutubeCC(url: string): Promise<string>getYoutubeCC(url: stringurl: string) {
const const browser: anybrowser = await import puppeteerpuppeteer.launch({
args: anyargs: import chromechrome.args,
executablePath: anyexecutablePath: await import chromechrome.executablePath,
headless: anyheadless: import chromechrome.headless
})
const const page: anypage = await const browser: anybrowser.newPage()
await const page: anypage.setRequestInterception(true)
let let ccUrl: stringccUrl = ''
const page: anypage.on('request', (request: anyrequest) => {
if (request: anyrequest.resourceType() === 'xhr') {
const const _ccUrl: any_ccUrl = request: anyrequest.url()
if (const _ccUrl: any_ccUrl.includes('https://www.youtube.com/api/timedtext')) {
let ccUrl: stringccUrl = const _ccUrl: any_ccUrl.replace('json3', 'vtt')
}
}
request: anyrequest.continue()
})
await const page: anypage.goto(url: stringurl, {
waitUntil: stringwaitUntil: 'networkidle0'
})
return let ccUrl: stringccUrl
}
(async () => {
const const ccUrl: stringccUrl = await function getYoutubeCC(url: string): Promise<string>getYoutubeCC(const youtubeEmbedUrl: stringyoutubeEmbedUrl)
})()Kita membuat instance peramban (browser) dan memasukkan opsi pengaturan untuk menggunakan Chrome AWS Lambda. Selain itu, kita juga menginisiasi halaman kosong baru.
Untuk mendapatkan pranala API caption YouTube, kita harus meng-intercept request peramban. Kita dapat melakukannya dengan memanggil setRequestInterception yang terdapat pada objek page dengan parameter true. Sekarang kita dapat membuat event listener untuk setiap event request. Setelah itu, kita harus menyaring request tersebut berdasarkan tipenya. Dalam hal ini kita harus mendapatkan request bertipe xhr.
Selanjutnya kita juga harus memerika apakah request bertipe xhr tersebut merupakan pranala API caption YouTube atau bukan. Jika ditemukan, maka kita harus mengubah format json3 menjadi vtt. Event callback ini dipanggil setiap peramban melakukan request. Sehingga kita harus memanggil fungsi continue secara manual untuk memanggil event request berikutnya.
Bagian terakhir dari bagian ini adalah memanggil fungsi goto dengan pranala embedded YouTube yang telah kita deklarasikan pada bagian sebelumnya sebagai parameter pertama. Kita juga menggunakan opsi waitUntil dengan nilai networkidle0. Opsi tersebut mendefinisikan bahwa kita akan menunggu hingga halaman selesai termuat secara menyeluruh.
Index Fetcher
Setelah kita mendapatkan pranala caption dari YouTube Closed Captions Fetcher, kita dapat mengambil data WebVTT-nya.
(async () => {
// previous code
const const data: Vtt[]data: type Vtt = {
id?: number;
start: number;
end: number;
text: string;
}
function fetch(input: RequestInfo | URL, init?: RequestInit): Promise<Response>[MDN Reference](https://developer.mozilla.org/docs/Web/API/Window/fetch)fetch(const ccUrl: stringccUrl)
.Promise<Response>.then<string, never>(onfulfilled?: ((value: Response) => string | PromiseLike<string>) | null | undefined, onrejected?: ((reason: any) => PromiseLike<never>) | null | undefined): Promise<string>Attaches callbacks for the resolution and/or rejection of the Promise.then((ccResponse: ResponseccResponse) => {
if (ccResponse: ResponseccResponse.Response.ok: booleanThe **`ok`** read-only property of the Response interface contains a Boolean stating whether the response was successful (status in the range 200-299) or not.
[MDN Reference](https://developer.mozilla.org/docs/Web/API/Response/ok)ok) {
return ccResponse: ResponseccResponse.Body.text(): Promise<string>[MDN Reference](https://developer.mozilla.org/docs/Web/API/Request/text)text()
}
return ''
})
.Promise<string>.then<Vtt[], Vtt[]>(onfulfilled?: ((value: string) => Vtt[] | PromiseLike<Vtt[]>) | null | undefined, onrejected?: ((reason: any) => Vtt[] | PromiseLike<Vtt[]>) | null | undefined): Promise<Vtt[]>Attaches callbacks for the resolution and/or rejection of the Promise.then((ccText: stringccText) => {
const const ccStriped: stringccStriped = function stripHtml(string: string): stringstripHtml(ccText: stringccText)
const const ccJson: CCNodeListccJson = function vttToJson(vtt: string): CCNodeListvttToJson(const ccStriped: stringccStriped)
const const ccData: Vtt[]ccData = const ccJson: CCNodeListccJson
.Array<CCNode>.filter(predicate: (value: CCNode, index: number, array: CCNode[]) => unknown, thisArg?: any): CCNode[] (+1 overload)Returns the elements of an array that meet the condition specified in a callback function.filter((item: CCNodeitem) => {
return item: CCNodeitem.type: "cue"type === 'cue'
})
.Array<CCNode>.map<{
start: number;
end: number;
text: string;
}>(callbackfn: (value: CCNode, index: number, array: CCNode[]) => {
start: number;
end: number;
text: string;
}, thisArg?: any): {
start: number;
end: number;
text: string;
}[]
item: CCNodeitem) => {
return {
start: numberstart: function toSecond(timestamp: number): numbertoSecond((item: CCNodeitem as type CCNode = {
type: "cue";
data: {
start: number;
end: number;
text: string;
settings?: string;
};
}
data: {
start: number;
end: number;
text: string;
settings?: string;
}
start: numberstart || 0),
end: numberend: function toSecond(timestamp: number): numbertoSecond((item: CCNodeitem as type CCNode = {
type: "cue";
data: {
start: number;
end: number;
text: string;
settings?: string;
};
}
data: {
start: number;
end: number;
text: string;
settings?: string;
}
end: numberend || 0),
text: stringtext: function stripWhitespaceNewLine(string: string): stringstripWhitespaceNewLine((item: CCNodeitem as type CCNode = {
type: "cue";
data: {
start: number;
end: number;
text: string;
settings?: string;
};
}
data: {
start: number;
end: number;
text: string;
settings?: string;
}
text: stringtext)
}
}) as type Vtt = {
id?: number;
start: number;
end: number;
text: string;
}
const ccData: Vtt[]ccData
})
})()Catatan:
CCNodemerupakan deklarasi tipe data yang saya buat sendiri untuk tujuan demo. Deklarasi tipe data asli yang berasal dari paket NPM subtitle adalahNodeCue.
Kita menggunakan fungsi fetch untuk mendapatkan datanya. Jika responnya sukses, kita dapat memanggil fungsi text dan mendapatkan data caption dalam bentuk teks. Jika responsennya gagal, kita hanya mengembalikan nilai string kosong.
Biasanya, data caption berisi kode HTML. Jadi kita harus menghilangkannya dengan memanggil fungsi stripHtml. Fungsi tersebut mengembalikan nilai dalam bentuk string juga. Untuk memudahkan kita berinteraksi dengan data tersebut, kita harus mengubahnya menjadi bentuk yang umum di JavaScript.
Kita mengubahnya menjadi objek JSON dengan cara memanggil fungsi vttToJson. Di balik layar, fungsi tersebut menggunakan fungsi parseSync dari paket NPM subtitle. Hasil nilai kembaliannya berupa array of object.
Terkadang item dari array tersebut tercampur antara header dan cue. Item yang kita butuhkan hanyalah cue, jadi kita harus memfilternya. Setelah itu, kita memetakan array tersebut menjadi bentuk objek yang kita butuhkan, waktu mulai, waktu berakhir dan teks caption.
Waktu mulai dan waktu berakhir terbaca dalam format mili detik tetapi skema pranala YouTube pada umumnya menggunakan waktu dalam format detik. Oleh karena itu kita harus mengubahnya menjadi format yang benar menggunakan fungsi utilitas toSecond. Fungsi tersebut hanyalah fungsi sederhana yang membulatkan pembagian nilai mili detik dengan 1000.
Terkadang properti teks berisi spasi dan garis baru di akhir kalimat. Kita dapat membersihkannya menggunakan fungsi utilitas stripWhitespaceNewLine.
Search Fetcher
Fetcher ini digunakan pada endpoint pencarian. Hal yang dilakukan adalah mendapatkan respon JSON dari endpoint indeks.
(async () => {
// previous code
const const indexEndpoint: stringindexEndpoint = `https://cari-teks-video-api.vercel.app/api/?url=${const youtubeUrl: stringyoutubeUrl}&paginated=0`
const const list: FetcherReturnTypelist: type FetcherReturnType = {
data: Vtt[];
}
function fetch(input: RequestInfo | URL, init?: RequestInit): Promise<Response>[MDN Reference](https://developer.mozilla.org/docs/Web/API/Window/fetch)fetch(const indexEndpoint: stringindexEndpoint)
.Promise<Response>.then<any, never>(onfulfilled?: ((value: Response) => any) | null | undefined, onrejected?: ((reason: any) => PromiseLike<never>) | null | undefined): Promise<any>Attaches callbacks for the resolution and/or rejection of the Promise.then((response: Responseresponse) => {
if (response: Responseresponse.Response.ok: booleanThe **`ok`** read-only property of the Response interface contains a Boolean stating whether the response was successful (status in the range 200-299) or not.
[MDN Reference](https://developer.mozilla.org/docs/Web/API/Response/ok)ok) {
return response: Responseresponse.Body.json(): Promise<any>[MDN Reference](https://developer.mozilla.org/docs/Web/API/Request/json)json()
}
return []
})
.Promise<any>.then<{
data: Vtt[];
}, FetcherReturnType>(onfulfilled?: ((value: any) => {
data: Vtt[];
} | PromiseLike<{
data: Vtt[];
}>) | null | undefined, onrejected?: ((reason: any) => FetcherReturnType | PromiseLike<FetcherReturnType>) | null | undefined): Promise<FetcherReturnType | {
data: Vtt[];
}>
data: Vtt[]data: type Vtt = {
id?: number;
start: number;
end: number;
text: string;
}
data: Vtt[]data
}
})
})()Secara default, ketika kita melakukan request ke endpoint indeks, responnya akan terpaginasi. Jadi kita harus menambahkan parameter paginated=0 untuk mendapatkan hasil keseluruhan.
ID Generator
Flexsearch membutuhkan setiap item memiliki identitas unik. Modul ini akan meng-generate identitas tersebut.
(async () => {
// previous code
const const generatedIdList: {
id: number;
start: number;
end: number;
text: string;
}[]
const list: Vtt[]list.Array<Vtt>.map<{
id: number;
start: number;
end: number;
text: string;
}>(callbackfn: (value: Vtt, index: number, array: Vtt[]) => {
id: number;
start: number;
end: number;
text: string;
}, thisArg?: any): {
id: number;
start: number;
end: number;
text: string;
}[]
item: Vttitem, id: numberid) => {
return {
...item: Vttitem,
id: numberid
}
})
})()Modul ini akan memetakan objek sebelumnya dan menambahkan properti baru untuk identitas. Nilai dari identitas tersebut dapat kita ambil dari indeks array setiap item.
Finder
Kita menggunakan paket NPM bernama Flexsearch untuk melakukan pencarian kata kunci. Berdasarkan uji coba yang disebutkan pada halaman GitHubnya, Flexsearch merupakan perpustakaan pencarian teks menyeluruh yang tercepat dan paling efisien penggunaan memorinya. Selain itu Flexsearch juga tanpa dependensi apapun.
import import FlexsearchFlexsearch from 'flexsearch'
(async () => {
// previous code
const const index: anyindex = import FlexsearchFlexsearch.create<type Vtt = {
id?: number;
start: number;
end: number;
text: string;
}
doc: {
id: string;
field: string[];
}
id: stringid: 'id',
field: string[]field: ['text']
}
})
const generatedIdList: Vtt[]generatedIdList.Array<Vtt>.forEach(callbackfn: (value: Vtt, index: number, array: Vtt[]) => void, thisArg?: any): voidPerforms the specified action for each element in an array.forEach((item: Vttitem) => {
const index: anyindex.add(item: Vttitem)
})
const const keyword: "education"keyword = 'education'
const const resultList: anyresultList = await const index: anyindex.search(const keyword: "education"keyword)
})()Pada mulanya kita membuat indeks dengan cara memanggil fungsi create. Kita memasukkan beberapa konfigurasi seperti nama key dari identitas dan nama key apa yang Flexsearch harus cari ketika melakukan pencarian.
Setelah itu, kita lakukan perulangan dan menambahkan setiap item ke dalam indeks dengan cara memanggil fungsi add. Jika kita ingin mencari kata kunci, yang perlu dilakukan hanyalah memanggil fungsi search dari objek index dengan kata kunci yang dimaksud sebagai parameter pertama. Nilai yang dihasilkan dari pemanggilan tersebut berupa array yang telah difilter sesuai dengan kata kunci.
Highlighter
Sayangnya, Flexsearch belum memiliki highlighter bawaan ataupun yang dapat kita ubah-ubah sendiri. Namun, kita dapat mengimplementasinya sendiri. Karena nilai yang dikembalikan dari fungsi search merupakan daftar yang telah difilter, kita dapat melakukan perulangan dan meng-highlight kata kunci yang ditemukan dengan tag HTML.
(async () => {
// previous code
function function (local function) replacer(match: string): stringreplacer(match: stringmatch: string) {
return `<mark class="cvt-highlight">${match: stringmatch}</mark>`
}
const const highlightedList: Vtt[]highlightedList: type Vtt = {
id?: number;
start: number;
end: number;
text: string;
}
const resultList: Vtt[]resultList.Array<Vtt>.map<{
text: string;
id?: number;
start: number;
end: number;
}>(callbackfn: (value: Vtt, index: number, array: Vtt[]) => {
text: string;
id?: number;
start: number;
end: number;
}, thisArg?: any): {
text: string;
id?: number;
start: number;
end: number;
}[]
item: Vttitem) => {
let let text: stringtext = ''
if (item: Vttitem.text: stringtext.String.includes(searchString: string, position?: number): booleanReturns true if searchString appears as a substring of the result of converting this
object to a String, at one or more positions that are
greater than or equal to position; otherwise, returns false.includes(const keyword: stringkeyword)) {
let text: stringtext = `${item: Vttitem.text: stringtext}`.String.replace(searchValue: {
[Symbol.replace](string: string, replacer: (substring: string, ...args: any[]) => string): string;
}, replacer: (substring: string, ...args: any[]) => string): string (+3 overloads)
var RegExp: RegExpConstructor
new (pattern: RegExp | string, flags?: string) => RegExp (+2 overloads)
const keyword: stringkeyword}`, 'gi'), function (local function) replacer(match: string): stringreplacer)
} else {
const const multipleWords: RegExpMatchArray | nullmultipleWords = const keyword: stringkeyword.String.match(matcher: {
[Symbol.match](string: string): RegExpMatchArray | null;
}): RegExpMatchArray | null (+1 overload)
const multipleWords: RegExpMatchArray | nullmultipleWords) {
let text: stringtext = `${item: Vttitem.text: stringtext}`.String.replace(searchValue: {
[Symbol.replace](string: string, replacer: (substring: string, ...args: any[]) => string): string;
}, replacer: (substring: string, ...args: any[]) => string): string (+3 overloads)
var RegExp: RegExpConstructor
new (pattern: RegExp | string, flags?: string) => RegExp (+2 overloads)
const multipleWords: RegExpMatchArraymultipleWords.Array<string>.join(separator?: string): stringAdds all the elements of an array into a string, separated by the specified separator string.join('|')}`, 'gi'),
function (local function) replacer(match: string): stringreplacer
)
}
}
return {
...item: Vttitem,
text: stringtext
}
})
})()Jika kata kunci yang digunakan hanya terdiri dari satu kata, kita menggunakan fungsi String.prototype.includes untuk mengecek apakah teks berisi kata kunci yang dimaksud. Jika ditemukan, maka kita dapat melakukan mekanisme highlighting.
Sedangkan jika kata kunci yang digunakan terdiri dari beberapa kata, kita tidak dapat menggunakan metode tersebut. Sebagai gantinya, kita menggabungkan setiap kata pada kata kunci tersebut menjadi format RegEx. Katakanlah kata kunci yang digunakan adalah current education, kita mengubahnya menjadi /current|education/gi. Sehingga ketika melakukan mekanisme highlighting, setiap kata akan memiliki pembungkusnya masing-masing.
Paginator
Modul ini mengubah array menjadi versi terpaginasinya. Saya menemukan jawaban ringkas dari StackOverflow yang dapat membantu kita menyelesaikan permasalahan ini, Mempaginasi Array JavaScript.
(async () => {
// previous code
const const pageNumber: 1pageNumber = 1
const const pageSize: 10pageSize = 10
const const paginatedList: Vtt[]paginatedList = const highlightedList: Vtt[]highlightedList
.Array<Vtt>.slice(start?: number, end?: number): Vtt[]Returns a copy of a section of an array.
For both start and end, a negative index can be used to indicate an offset from the end of the array.
For example, -2 refers to the second to last element of the array.slice((const pageNumber: 1pageNumber - 1) * const pageSize: 10pageSize, const pageNumber: 1pageNumber * const pageSize: 10pageSize)
})()Satu-satunya parameter yang kita butuhkan adalah nomor halaman dan banyaknya item. Nomor halaman adalah halaman saat ini yang akan dikembalikan dan banyaknya item adalah berapa banyak item yang akan dikembalikan.
ID Remover
Identitas yang ditambahkan oleh modul ID Generator hanya digunakan untuk membuat indeks untuk pencarian. Di sini kita sudah tidak membutuhkannya dan dapat dihapus.
(async () => {
// previous code
const const removedIdList: Vtt[]removedIdList = const paginatedList: Vtt[]paginatedList.Array<Vtt>.map<Vtt>(callbackfn: (value: Vtt, index: number, array: Vtt[]) => Vtt, thisArg?: any): Vtt[]Calls a defined callback function on each element of an array, and returns an array that contains the results.map((item: Vttitem) => {
delete item: Vttitem.id?: number | undefinedid
return item: Vttitem
})
})()Untuk menghapus identitas tersebut, kita dapat melakukan pemetaan pada array menjadi array yang baru dan menghapus properti id.
Formatter
Modul terakhir adalah formatter. Kita tidak akan membahas terlalu panjang bagaimana modul ini terimplementasi. Tetapi secara garis besar modul ini akan menghasilkan pranala untuk halaman sebelumnya, selanjutnya, pertama dan terakhir.
(async () => {
// previous code
const const options: FormatterOptionsoptions: type FormatterOptions = {
reqUrl: string;
page: number;
size: number;
dataLength: number;
}
reqUrl: stringreqUrl: 'https://cari-teks-video-api.vercel.app/api',
page: numberpage: const pageNumber: numberpageNumber,
size: numbersize: const pageSize: numberpageSize,
dataLength: numberdataLength: const removedIdList: Vtt[]removedIdList.Array<Vtt>.length: numberGets or sets the length of the array. This is a number one higher than the highest index in the array.length
}
const const response: FormatterReturnTyperesponse: type FormatterReturnType = {
first: string;
last: string;
prev: string;
next: string;
total: number;
page: number;
data: Vtt[];
}
first: stringfirst: function getPaginationUrl(type: PaginationUrlType, options: FormatterOptions): stringgetPaginationUrl(enum PaginationUrlTypePaginationUrlType.function (enum member) PaginationUrlType.FirstFirst, const options: FormatterOptionsoptions),
last: stringlast: function getPaginationUrl(type: PaginationUrlType, options: FormatterOptions): stringgetPaginationUrl(enum PaginationUrlTypePaginationUrlType.function (enum member) PaginationUrlType.LastLast, const options: FormatterOptionsoptions),
prev: stringprev: function getPaginationUrl(type: PaginationUrlType, options: FormatterOptions): stringgetPaginationUrl(enum PaginationUrlTypePaginationUrlType.function (enum member) PaginationUrlType.PrevPrev, const options: FormatterOptionsoptions),
next: stringnext: function getPaginationUrl(type: PaginationUrlType, options: FormatterOptions): stringgetPaginationUrl(enum PaginationUrlTypePaginationUrlType.function (enum member) PaginationUrlType.NextNext, const options: FormatterOptionsoptions),
total: numbertotal: const options: FormatterOptionsoptions.dataLength: numberdataLength,
page: numberpage: const options: FormatterOptionsoptions.page: numberpage,
data: Vtt[]data: const removedIdList: Vtt[]removedIdList
}
})()Fungsi getPaginationRul menerima 2 parameter, parameter pertama berupa enum TypeScript. Enum tersebut berfungsi untuk mengidentifikasi paginasi yang mana yang sedang berlangsung. Parameter kedua adalah opsi yang terdiri dari:
reqUrl, request pranala saat ini. Jika saat ini request ke endpoint indeks maka pranalanya berakhiran/. Dan jika request ke endpoint pencarian, maka pranalanya berakhiran/search.page, halaman pencarian saat ini, secara default nilai dari opsi ini adalah halaman pertama.size, berapa banyak hasil yang harus dikembalikan oleh API, secara default nilai dari opsi ini adalah 10 item.dataLength, berapa banyak data sebelum terpaginasi.
Artikel ini hanya membahas bagian penting dari keseluruhan kode sumber. Jika teman-teman ingin mengetahui bagaimana penerapan nyatanya, teman-teman dapat mempelajarinya di repositori GitHub berikut, Cari Teks Video API.
Penyangkalan
- “Metode” mengarah ke langkah-langkah atau penjelasan yang saya tulis pada artikel ini.
- “API” mengarah ke semua API yang tersedia pada https://cari-teks-video-api.vercel.app/api.
- Semua metode ini murni bertujuan untuk riset dan eksperimen.
- Jika YouTube memutuskan untuk mengubah skema API caption atau menggunakan cara lain, metode ini kemungkinan tidak dapat digunakan.
- Karena API yang dibuat di-host pada versi gratis dari Vercel yang memiliki beberapa batasan. Salah satunya adalah berapa banyak pemanggilan fungsi. Jika API tersebut tiba-tiba tidak dapat diakses, kemungkinan telah melewati batasan tersebut.
- Karena poin nomor 4 dan 5, saya tidak dapat menjamin API tersebut akan dapat digunakan secara terus-menerus. Tetapi saya akan melakukan pengecekan secara reguler untuk memastikannya tetap berjalan baik.
- Jangan gunakan untuk production. Saya tidak akan bertanggung jawab terhadap dampak apapun yang ditimbulkan dari penggunaan tersebut.
- YouTube memiliki API Data YouTube untuk Caption untuk menyediakan cara resmi mengakses caption. Silahkan gunakan layanan ini jika teman-teman ingin menggunakan fitur serupa untuk production.
- Jika teman-teman menemukan bug, silahkan mengirimkan issue di repositori GitHub berikut, Cari Teks Video API.
Referensi
- GitHub: Cari Teks Video API Docs
- GitHub: Search web.dev Live by Sam Dutton
- Google Developers Portal: API Data YouTube untuk Caption
- StackOverflow: Mempaginasi Javascript Array
- StackOverflow: Regex untuk ID YouTube