What If We Could Search Any Keyword from Any YouTube Video through Its Closed Captions Text?
YouTube Closed Captions Search Demo
"Video Title" byChannel Name
Note:
- Only YouTube video that has English subtitle is supported.
- Can't be used on copyrighted YouTube video, such as music video.
- Each YouTube URL takes a longer time to search at first because the cache isn't available yet.
- To minimize the data usage, the auto demo feature only runs if this demo section is visible on your browser viewport.
Not looking for any keyword, try enter some keyword.
Timer: 15s
0 search results found. Currently on page 0
TLDR
Last year, I got an idea to create a web app that can search keyword from people speech in a YouTube video. That idea came up when I was watching web.dev Live event. Not using any sophisticated and bleeding-edge technology, only via closed captions text.
When we activate closed captions on YouTube, the page requests to an API. It responses a JSON object that we can customize into WebVTT format. Unfortunately, the YouTube closed captions API is equipped with some parameters. They have a unique identifier and expiration date.
Because of that, we can’t access the URL frequently. Luckily, each YouTube video has a unique identifier on its URL. Not just URL for regular YouTube page, but also for its embedded version. We can use of puppeteer to request that embedded page and intercept the request to get the API.
We process further the closed captions data we get using several open-source NPM packages and turn that into our REST API. This API only needs a YouTube URL and a keyword. We host the API service in Vercel.
Take a look at the documentation on Cari Teks Video API and a list of awesome projects that already use this REST API on Awesome Cari Teks Video. You can also continue to read this post to learn more about the implementation.
Backstory
On the 30th of June until 2nd of July 2020, Chrome Developer Advocate team held a very spectacular online event for web developers. It was web.dev Live.
I was watching the event until one of Chrome Developer Advocate, Sam Dutton shared a link in the chatbox. I navigated to that link and it turned out was a web app for search, navigate closed captions from web.dev Live event video.
The web app is called Search web.dev Live. I was impressed that we can search something from a video. Despite that was just from the closed captions. I looked over at the GitHub link on the footer to see what’s the underlying technology.
No bleeding-edge technology is used. No machine learning nor complex algorithm is involved. Only a simple JavaScript, several NPM packages and closed captions files. It’s intriguing to know that.
I guessed the problem with Search web.dev Live is it only search on the web.dev Live event video. Anyway, the web.dev Live event video was hosted on YouTube. And the closed captions files for the web app are stored on the repository itself.
“What if we could do that for all video on YouTube?”, I wandered. Based on my assumption, the algorithm will look like this:
- The JavaScript took the keyword from the input.
- Searches the keyword from all closed captions files.
- Highlights the result.
Just as effortless as like that. And it took me for a couple of searches to find that we can get YouTube closed captions from a specific link.
First, we must open a YouTube video then enable the closed captions to get that specific link.
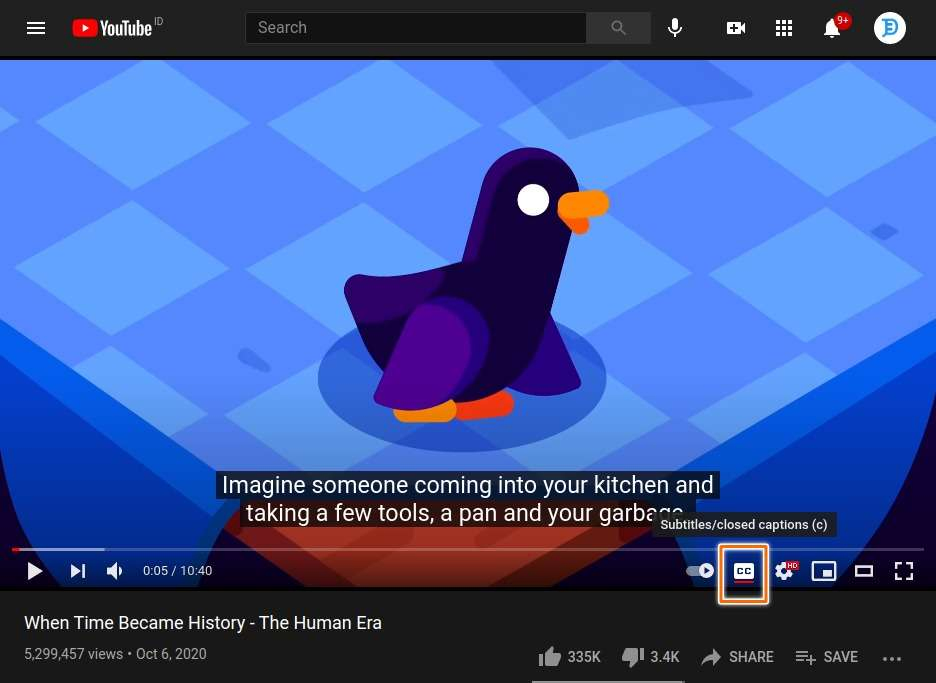
After enabling the closed captions feature, YouTube will make a new request from some kind of API. The response is the closed captions of the video.
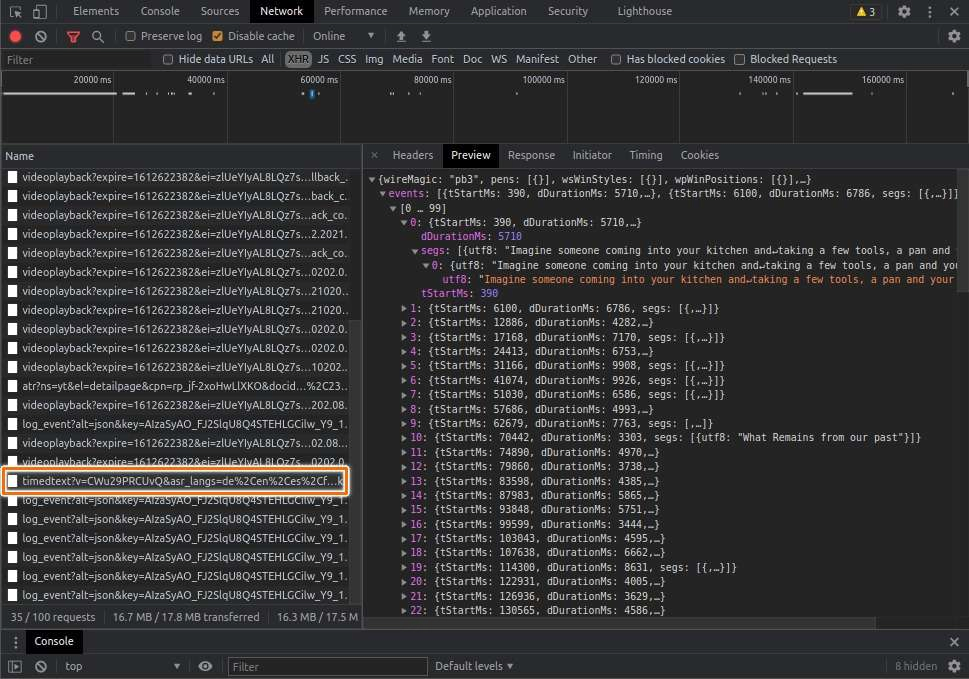
This is the example of the API URL:
const const ccUrl: "https://www.youtube.com/api/timedtext?v=CWu29PRCUvQ&asr_langs=de%2Cen%2Ces%2Cfr%2Cit%2Cja%2Cko%2Cnl%2Cpt%2Cru&caps=asr&exp=xftt&xorp=true&xoaf=5&hl=en&ip=0.0.0.0&ipbits=0&expire=1612625982&sparams=ip%2Cipbits%2Cexpire%2Cv%2Casr_langs%2Ccaps%2Cexp%2Cxorp%2Cxoaf&signature=CC705091625358E3A3883C981A21BFC4F6E35569.77DAB826C17A839CEE703DB894D73D8AECCA0AE2&key=yt8&lang=en-GB&fmt=json3&xorb=2&xobt=3&xovt=3"ccUrl = 'https://www.youtube.com/api/timedtext?v=CWu29PRCUvQ&asr_langs=de%2Cen%2Ces%2Cfr%2Cit%2Cja%2Cko%2Cnl%2Cpt%2Cru&caps=asr&exp=xftt&xorp=true&xoaf=5&hl=en&ip=0.0.0.0&ipbits=0&expire=1612625982&sparams=ip%2Cipbits%2Cexpire%2Cv%2Casr_langs%2Ccaps%2Cexp%2Cxorp%2Cxoaf&signature=CC705091625358E3A3883C981A21BFC4F6E35569.77DAB826C17A839CEE703DB894D73D8AECCA0AE2&key=yt8&lang=en-GB&fmt=json3&xorb=2&xobt=3&xovt=3'Let’s breakdown the URL’s query param into detail:
{
"v": "CWu29PRCUvQ",
"asr_langs": "de,en,es,fr,it,ja,ko,nl,pt,ru",
"caps": "asr",
"exp": "xftt",
"xorp": "true",
"xoaf": "5",
"hl": "en",
"ip": "0.0.0.0",
"ipbits": "0",
"expire": "1612625982",
"sparams": "ip,ipbits,expire,v,asr_langs,caps,exp,xorp,xoaf",
"signature": "CC705091625358E3A3883C981A21BFC4F6E35569.77DAB826C17A839CEE703DB894D73D8AECCA0AE2",
"key": "yt8",
"lang": "en-GB",
"fmt": "json3",
"xorb": "2",
"xobt": "3",
"xovt": "3"
}We can get some of the understandable key-value pairs here:
vmeans YouTube video identity.hlif I’m not mistaken, it stands for host language. It is common for Google-related API service to use this key. This key is for defining something related to language setting. For this case, it seems for the language of the closed captions.expirewhen will the API request expired. It seems the value is in seconds unit.signaturesome random identifier of the request. In my opinion, the value of this key defines which request is eligible to process. The expiration date seems also has connection to this identifier. I try to remove this identifier when accessing the API but it responses failed.fmtis the response format. By default, the API response is formatted asjson3. My bet is the value can be customized. I try another closed captions format, such asvttand it does work.
We still have a bunch of more, but those are the most important key values we need.
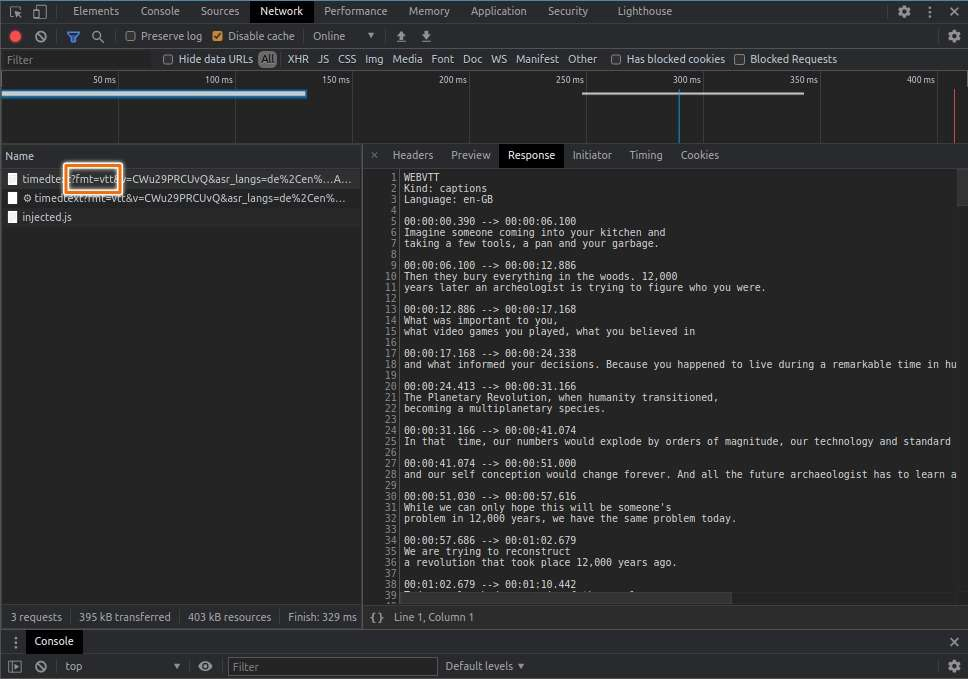
Viola! I think we use that API URL to build our general YouTube video search through closed captions web app.
Before we continue, let’s first take a glance look at the content of WebVTT format:
WEBVTT
Kind: captions
Language: en
00:00:00.357 --> 00:00:01.822
- [Narrator] There is
a growing feeling today
00:00:01.822 --> 00:00:04.699
that something is wrong with
our system of education.WebVTT is just a regular text with some specific content formatting. As an outline, WebVTT consist of 2 things. They are the header and the cue.
WEBVTT
Kind: captions
Language: enThe header contains metadata about the closed captions itself, like the content language of WebVTT or the creator.
00:00:00.357 --> 00:00:01.822
- [Narrator] There is
a growing feeling today
00:00:01.822 --> 00:00:04.699
that something is wrong with
our system of education.The cue can be divided into 3 parts, they are start time, end time and the text. The text is the closed captions text that will be shown on the video. The start time represents when will the text is shown. The last part is the end time, indicate when will the text disappears.
Ingredients
Here are several key NPM packages we can use to create the API:
- @vercel/node, we host the API on Vercel so we need this package to build and serve our API there.
- chrome-aws-lambda, Vercel Serverless Function under the hood is run on AWS Lambda. It has a limitation on how big the function size. If I’m not mistaken, the maximum size is around 50MB and unzipped size is around 250MB. To comply with that limitation, we can’t use regular puppeteer package. Because it will download the full size of the chrome browser when installed. Instead, we use puppeteer-core and with this package as companion. This package will install smaller size of chrome because it is compressed using Brotli algorithm.
- flexsearch, we want to create a search API, so we need to have searching mechanism. Even though we can use native
Array.prototype.filtermethod, in my opinion, it will be better if we could increase the performance by using a 3rd party library. Search web.dev Live web app also uses this package. - get-urls, this package is very useful to extract metadata link from a string. Specifically to get the YouTube logo URL.
- isomorphic-fetch, we will use this package to fetch the closed captions data from YouTube REST API.
- joi, this package is for object validation. It makes sure all the data is in the correct format.
- pino-logflare, a log is a very crucial part of any technology. We can use that to debug and fix any issue. However, Vercel has different behaviour of storing the log. In short, it’s quite difficult to get insightful information from the log because of Vercel’s limitation. Luckily, Vercel also provides a feature called Log Drain. In a nutshell, instead of storing log in Vercel server, they will pipe the log directly into another service that specializes in storing app logs. One of them is Logflare. This package integrates pino express logger and Logflare.
- puppeteer-core, puppeteer is headless chrome, we need this package to open the YouTube page.
- string-strip-html, sometimes the closed captions contain HTML code. We need this package to remove them all.
- subtitle, we get the closed captions from YouTube API in the form of WebVTT. This package is useful for parse and converts that format into a JavaScript object.
- typescript, enhanced version of JavaScript.
For more detail packages please take a look on the package.json file on this repository, Cari Teks Video API.
Modules
We already have all the ingredients. We will create 2 API endpoints, the first one is the / and the second one is the /search. Index endpoint is only used to fetch the closed captions data from YouTube. For search endpoint is for search. In this post, we will discuss more for search endpoint.
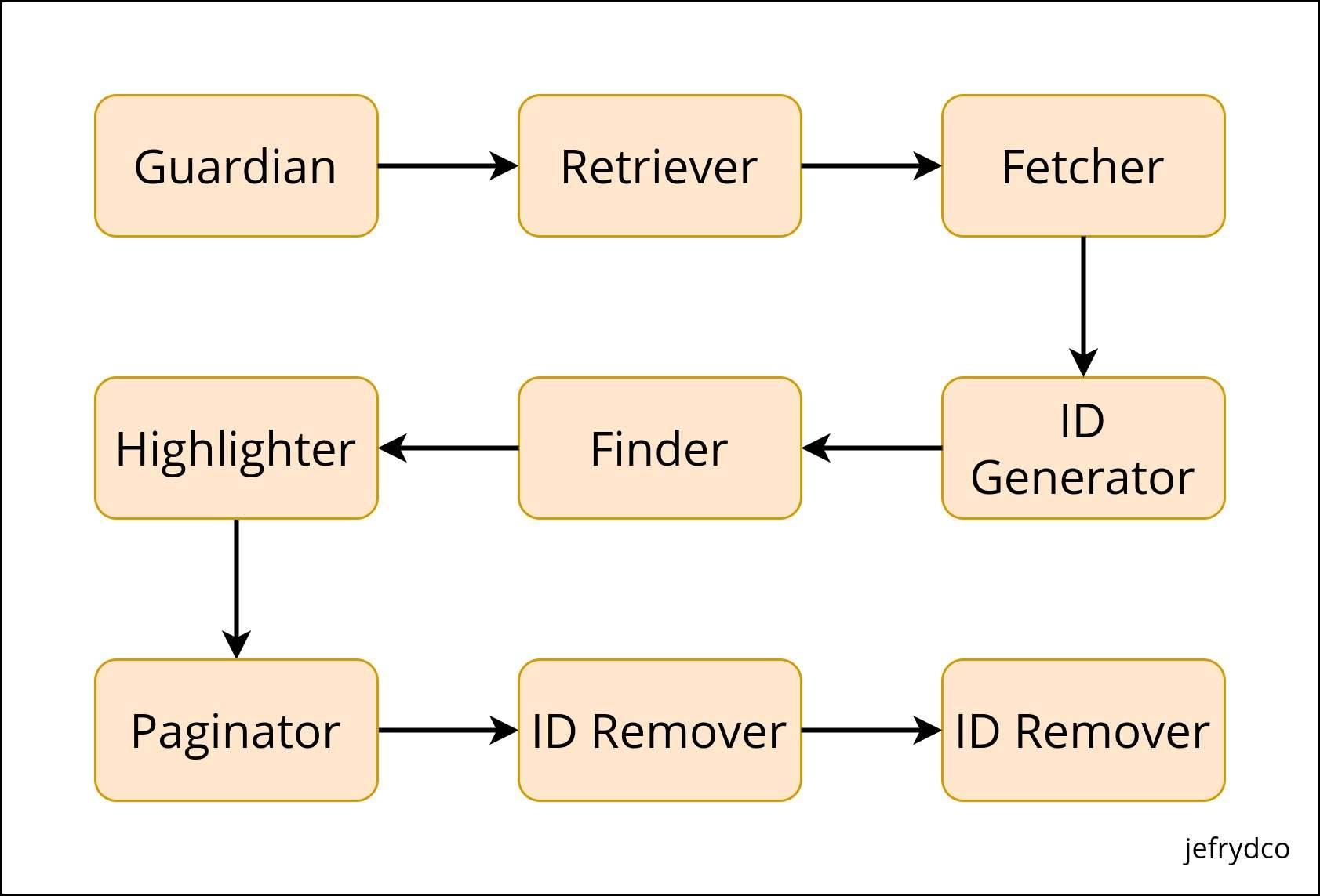
Based on the diagram above, we can split our REST API into 8 smaller modules.
Guardian
As its name suggests, the function of this module is the guardian. Which is to make sure all the incoming parameter and the data containing are correct. We use Joi as our guardian.
In our case, the incoming parameter is from query param.
import import joijoi from 'joi'
const const indexQuery: anyindexQuery = import joijoi.object({
url: anyurl: import joijoi.string().required(),
page: anypage: import joijoi.string().optional(),
size: anysize: import joijoi.string().optional(),
paginated: anypaginated: import joijoi.number().integer().allow(0, 1).optional()
})
const const searchQuery: anysearchQuery = const indexQuery: anyindexQuery.keys({
q: anyq: import joijoi.string().min(3).required(),
marked: anymarked: import joijoi.number().integer().allow(0, 1).optional()
})Following our REST API endpoint, there are 2 kinds of query params. The first one is for index and the second one is for search. The search query params are just extending the index.
If you want to know what is the function of each query param. Please learn more on the Cari Teks Video API Docs - Request.
Retriever
Retriever is used to retrieve the data from query param that passed on the REST API. Like we did on the Guardian, we also need to split the retriever into 2 kinds of function, index and search.
For url, we pass directly the YouTube URL to the REST API. But if we open the regular YouTube page, it will take a longer time. Instead, we can use the YouTube embeded page. So we need to convert that regular YouTube URL into its embed version.
We need to get the video identity from the URL. We can use a Regular Expression for that. Here the RegEx I use to extract video identity from YouTube URL:
const const youtubeUrl: "https://www.youtube.com/watch?v=okpg-lVWLbE"youtubeUrl = 'https://www.youtube.com/watch?v=okpg-lVWLbE'
const const result: RegExpExecArray | nullresult = /(?:youtube\.com\/(?:[^\/]+\/.+\/|(?:v|e(?:mbed)?)\/|.*[?&]v=)|youtu\.be\/)([^"&?\/\s]{11})/gi
.RegExp.exec(string: string): RegExpExecArray | nullExecutes a search on a string using a regular expression pattern, and returns an array containing the results of that search.exec(const youtubeUrl: "https://www.youtube.com/watch?v=okpg-lVWLbE"youtubeUrl)
let let id: stringid = ''
if (var Array: ArrayConstructorArray.ArrayConstructor.isArray(arg: any): arg is any[]isArray(const result: RegExpExecArray | nullresult) && const result: RegExpExecArrayresult.Array<string>.length: numberGets or sets the length of the array. This is a number one higher than the highest index in the array.length > 0) {
let id: stringid = const result: RegExpExecArrayresult[1]
}A quite long RegEx but it does work. I get that RegEx from this StackOverflow thread, Regex for YouTube ID.
After we get the video identity then we have to pass it to the YouTube embed URL.
// previous code
const const youtubeEmbedUrl: stringyoutubeEmbedUrl = `https://www.youtube.com/embed/${const id: stringid}?hl=en&cc_lang_pref=en&cc_load_policy=1&autoplay=1`We also add several parameters to that URL.
hl, same ashlfrom YouTube Closed Captions API we already discussed above. It stands for the host language. The function is for setting the player interface language.cc_lang_pref, it specifies the default language for displaying closed captions.cc_load_policy, makes the closed captions automatically shown by default if the value is1.autoplay, set to play the video automatically if the value is1.
Fetcher
Probably this module is the most time consuming to make. It contains a function to fetch the YouTube Closed Captions API, index fetcher and search fetcher.
YouTube Closed Captions Fetcher
This fetcher is actually used in index endpoint. But to get a better understanding of how we get the closed captions data, we should get into this.
We already know the algorithm to get the YouTube Closed Captions API URL. But we need to convert that algorithm into real code. We use puppeteer and Chrome AWS Lambda to do that. Let’s take a look the snippet below:
import import chromechrome from 'chrome-aws-lambda'
import import puppeteerpuppeteer from 'puppeteer-core'
async function function getYoutubeCC(url: string): Promise<string>getYoutubeCC(url: stringurl: string) {
const const browser: anybrowser = await import puppeteerpuppeteer.launch({
args: anyargs: import chromechrome.args,
executablePath: anyexecutablePath: await import chromechrome.executablePath,
headless: anyheadless: import chromechrome.headless
})
const const page: anypage = await const browser: anybrowser.newPage()
await const page: anypage.setRequestInterception(true)
let let ccUrl: stringccUrl = ''
const page: anypage.on('request', (request: anyrequest) => {
if (request: anyrequest.resourceType() === 'xhr') {
const const _ccUrl: any_ccUrl = request: anyrequest.url()
if (const _ccUrl: any_ccUrl.includes('https://www.youtube.com/api/timedtext')) {
let ccUrl: stringccUrl = const _ccUrl: any_ccUrl.replace('json3', 'vtt')
}
}
request: anyrequest.continue()
})
await const page: anypage.goto(url: stringurl, {
waitUntil: stringwaitUntil: 'networkidle0'
})
return let ccUrl: stringccUrl
}
(async () => {
const const ccUrl: stringccUrl = await function getYoutubeCC(url: string): Promise<string>getYoutubeCC(const youtubeEmbedUrl: stringyoutubeEmbedUrl)
})()We launch a browser instance and then pass the options to use the Chrome AWS Lambda configuration. Besides that, we also initiate a new empty page.
To get the YouTube Closed Captions API, we have to intercept the request. We can do that by calling setRequestInterception from page instance with true argument. Now, we can listen to the request event. After that, we need to filter out the request by its resource type. For this case we have to get any xhr request.
Then we also check the URL whether its YouTube Closed Captions API or not. If its found, we replace the json3 format to vtt. This callback event is called on every request browser made. So we need to manually call continue method to call the next request event.
The last part of this section is calling the goto method with YouTube embed URL we already form on previous section as the first argument. We also pass the waitUntil option with value networkidle0. The option means that we will wait the page until its fully loaded.
Index Fetcher
After we get the closed captions url from YouTube Closed Captions Fetcher, we have to fetch the WebVTT data. That is the function of this fetcher.
(async () => {
// previous code
const const data: Vtt[]data: type Vtt = {
id?: number;
start: number;
end: number;
text: string;
}
function fetch(input: RequestInfo | URL, init?: RequestInit): Promise<Response>[MDN Reference](https://developer.mozilla.org/docs/Web/API/Window/fetch)fetch(const ccUrl: stringccUrl)
.Promise<Response>.then<string, never>(onfulfilled?: ((value: Response) => string | PromiseLike<string>) | null | undefined, onrejected?: ((reason: any) => PromiseLike<never>) | null | undefined): Promise<string>Attaches callbacks for the resolution and/or rejection of the Promise.then((ccResponse: ResponseccResponse) => {
if (ccResponse: ResponseccResponse.Response.ok: booleanThe **`ok`** read-only property of the Response interface contains a Boolean stating whether the response was successful (status in the range 200-299) or not.
[MDN Reference](https://developer.mozilla.org/docs/Web/API/Response/ok)ok) {
return ccResponse: ResponseccResponse.Body.text(): Promise<string>[MDN Reference](https://developer.mozilla.org/docs/Web/API/Request/text)text()
}
return ''
})
.Promise<string>.then<Vtt[], Vtt[]>(onfulfilled?: ((value: string) => Vtt[] | PromiseLike<Vtt[]>) | null | undefined, onrejected?: ((reason: any) => Vtt[] | PromiseLike<Vtt[]>) | null | undefined): Promise<Vtt[]>Attaches callbacks for the resolution and/or rejection of the Promise.then((ccText: stringccText) => {
const const ccStriped: stringccStriped = function stripHtml(string: string): stringstripHtml(ccText: stringccText)
const const ccJson: CCNodeListccJson = function vttToJson(vtt: string): CCNodeListvttToJson(const ccStriped: stringccStriped)
const const ccData: Vtt[]ccData = const ccJson: CCNodeListccJson
.Array<CCNode>.filter(predicate: (value: CCNode, index: number, array: CCNode[]) => unknown, thisArg?: any): CCNode[] (+1 overload)Returns the elements of an array that meet the condition specified in a callback function.filter((item: CCNodeitem) => {
return item: CCNodeitem.type: "cue"type === 'cue'
})
.Array<CCNode>.map<{
start: number;
end: number;
text: string;
}>(callbackfn: (value: CCNode, index: number, array: CCNode[]) => {
start: number;
end: number;
text: string;
}, thisArg?: any): {
start: number;
end: number;
text: string;
}[]
item: CCNodeitem) => {
return {
start: numberstart: function toSecond(timestamp: number): numbertoSecond((item: CCNodeitem as type CCNode = {
type: "cue";
data: {
start: number;
end: number;
text: string;
settings?: string;
};
}
data: {
start: number;
end: number;
text: string;
settings?: string;
}
start: numberstart || 0),
end: numberend: function toSecond(timestamp: number): numbertoSecond((item: CCNodeitem as type CCNode = {
type: "cue";
data: {
start: number;
end: number;
text: string;
settings?: string;
};
}
data: {
start: number;
end: number;
text: string;
settings?: string;
}
end: numberend || 0),
text: stringtext: function stripWhitespaceNewLine(string: string): stringstripWhitespaceNewLine((item: CCNodeitem as type CCNode = {
type: "cue";
data: {
start: number;
end: number;
text: string;
settings?: string;
};
}
data: {
start: number;
end: number;
text: string;
settings?: string;
}
text: stringtext)
}
}) as type Vtt = {
id?: number;
start: number;
end: number;
text: string;
}
const ccData: Vtt[]ccData
})
})()Note:
CCNodeis a type declaration I created for demo purpose. The original type declaration from subtitle package isNodeCue.
We use fetch method to get the data. If everything is good, we will call the text method and get the closed captions data in form of text. If not, we just return an empty string.
Usually, the closed captions contain HTML code. So we need to remove that by calling the stripHtml method. The return is still a string so we need to convert that into an easier form to interact with.
We convert that into a JSON object by calling the vttToJson method. Behind the scenes, that method uses parseSync from subtitle package. It returns an array of object.
Sometimes the item is mixed up between header and cue type. The only thing we need is the cue, so we should filter that out. After that, we map through the array to get the data we need. They are start time, end time and closed captions text.
Start time and end time originally parsed as millisecond but YouTube URL scheme mostly use time in seconds format. We have to convert them into the right format using toSecond utils method. It just a simple method that round division of millisecond with 1000.
For the text property, it often contains unnecessary whitespace and new line at the end of the sentence. We can clean them up using stripWhitespaceNewLine utils method.
Search Fetcher
This fetcher is used in search endpoint. It fetches the JSON response from index endpoint.
(async () => {
// previous code
const const indexEndpoint: stringindexEndpoint = `https://cari-teks-video-api.vercel.app/api/?url=${const youtubeUrl: stringyoutubeUrl}&paginated=0`
const const list: FetcherReturnTypelist: type FetcherReturnType = {
data: Vtt[];
}
function fetch(input: RequestInfo | URL, init?: RequestInit): Promise<Response>[MDN Reference](https://developer.mozilla.org/docs/Web/API/Window/fetch)fetch(const indexEndpoint: stringindexEndpoint)
.Promise<Response>.then<any, never>(onfulfilled?: ((value: Response) => any) | null | undefined, onrejected?: ((reason: any) => PromiseLike<never>) | null | undefined): Promise<any>Attaches callbacks for the resolution and/or rejection of the Promise.then((response: Responseresponse) => {
if (response: Responseresponse.Response.ok: booleanThe **`ok`** read-only property of the Response interface contains a Boolean stating whether the response was successful (status in the range 200-299) or not.
[MDN Reference](https://developer.mozilla.org/docs/Web/API/Response/ok)ok) {
return response: Responseresponse.Body.json(): Promise<any>[MDN Reference](https://developer.mozilla.org/docs/Web/API/Request/json)json()
}
return []
})
.Promise<any>.then<{
data: Vtt[];
}, FetcherReturnType>(onfulfilled?: ((value: any) => {
data: Vtt[];
} | PromiseLike<{
data: Vtt[];
}>) | null | undefined, onrejected?: ((reason: any) => FetcherReturnType | PromiseLike<FetcherReturnType>) | null | undefined): Promise<FetcherReturnType | {
data: Vtt[];
}>
data: Vtt[]data: type Vtt = {
id?: number;
start: number;
end: number;
text: string;
}
data: Vtt[]data
}
})
})()By default when we request to index endpoint, the response will be paginated. So we need to pass paginated=0 to get the full result.
ID Generator
FLexsearch requires each item in the data to have a unique identity. This module generates it for them.
(async () => {
// previous code
const const generatedIdList: {
id: number;
start: number;
end: number;
text: string;
}[]
const list: Vtt[]list.Array<Vtt>.map<{
id: number;
start: number;
end: number;
text: string;
}>(callbackfn: (value: Vtt, index: number, array: Vtt[]) => {
id: number;
start: number;
end: number;
text: string;
}, thisArg?: any): {
id: number;
start: number;
end: number;
text: string;
}[]
item: Vttitem, id: numberid) => {
return {
...item: Vttitem,
id: numberid
}
})
})()It maps the existing object and adds new property for identity to them. The identity value is taken from the array index of each item.
Finder
We use an NPM package called Flexsearch to search for any keyword. Based on benchmark stated on its GitHub page, Flexsearch is the web’s fastest and most memory-flexible full-text search library with zero dependencies.
import import FlexsearchFlexsearch from 'flexsearch'
(async () => {
// previous code
const const index: anyindex = import FlexsearchFlexsearch.create<type Vtt = {
id?: number;
start: number;
end: number;
text: string;
}
doc: {
id: string;
field: string[];
}
id: stringid: 'id',
field: string[]field: ['text']
}
})
const generatedIdList: Vtt[]generatedIdList.Array<Vtt>.forEach(callbackfn: (value: Vtt, index: number, array: Vtt[]) => void, thisArg?: any): voidPerforms the specified action for each element in an array.forEach((item: Vttitem) => {
const index: anyindex.add(item: Vttitem)
})
const const keyword: "education"keyword = 'education'
const const resultList: anyresultList = await const index: anyindex.search(const keyword: "education"keyword)
})()First, we must build an index by calling create method. We pass some configurations like what is the name of the identity key and what is the key name that Flexsearch need to look.
After that, we loop through the list and add each item to the index by calling add method. If we want to search a keyword, we just call search method from index object with the keyword as a parameter. The return of this call is the filtered list matched the keyword.
Highlighter
Unfortunately, Flexsearch doesn’t come with a built-in highlighter nor the custom one. We need to implement that ourself. Because of the return of search is filtered list, we just need to loop through that list and wrap the keyword with some HTML tag.
(async () => {
// previous code
function function (local function) replacer(match: string): stringreplacer(match: stringmatch: string) {
return `<mark class="cvt-highlight">${match: stringmatch}</mark>`
}
const const highlightedList: Vtt[]highlightedList: type Vtt = {
id?: number;
start: number;
end: number;
text: string;
}
const resultList: Vtt[]resultList.Array<Vtt>.map<{
text: string;
id?: number;
start: number;
end: number;
}>(callbackfn: (value: Vtt, index: number, array: Vtt[]) => {
text: string;
id?: number;
start: number;
end: number;
}, thisArg?: any): {
text: string;
id?: number;
start: number;
end: number;
}[]
item: Vttitem) => {
let let text: stringtext = ''
if (item: Vttitem.text: stringtext.String.includes(searchString: string, position?: number): booleanReturns true if searchString appears as a substring of the result of converting this
object to a String, at one or more positions that are
greater than or equal to position; otherwise, returns false.includes(const keyword: stringkeyword)) {
let text: stringtext = `${item: Vttitem.text: stringtext}`.String.replace(searchValue: {
[Symbol.replace](string: string, replacer: (substring: string, ...args: any[]) => string): string;
}, replacer: (substring: string, ...args: any[]) => string): string (+3 overloads)
var RegExp: RegExpConstructor
new (pattern: RegExp | string, flags?: string) => RegExp (+2 overloads)
const keyword: stringkeyword}`, 'gi'), function (local function) replacer(match: string): stringreplacer)
} else {
const const multipleWords: RegExpMatchArray | nullmultipleWords = const keyword: stringkeyword.String.match(matcher: {
[Symbol.match](string: string): RegExpMatchArray | null;
}): RegExpMatchArray | null (+1 overload)
const multipleWords: RegExpMatchArray | nullmultipleWords) {
let text: stringtext = `${item: Vttitem.text: stringtext}`.String.replace(searchValue: {
[Symbol.replace](string: string, replacer: (substring: string, ...args: any[]) => string): string;
}, replacer: (substring: string, ...args: any[]) => string): string (+3 overloads)
var RegExp: RegExpConstructor
new (pattern: RegExp | string, flags?: string) => RegExp (+2 overloads)
const multipleWords: RegExpMatchArraymultipleWords.Array<string>.join(separator?: string): stringAdds all the elements of an array into a string, separated by the specified separator string.join('|')}`, 'gi'),
function (local function) replacer(match: string): stringreplacer
)
}
}
return {
...item: Vttitem,
text: stringtext
}
})
})()If the keyword is a single word keyword, we use String.prototype.includes method to check whether the text contains the corresponding keyword. If it is found then we do wrapping mechanism.
Meanwhile, if the keyword consists of multiple words we can’t use that method. Instead, we concatenate each word into a RegEx format. Let say if the keyword is current education, we turn that into /current|education/gi. So each word will get the wrap itself.
Paginator
This module turns a full array into paginated version. I found a very concise answer from StackOverflow that help me get through this, Paginate Javascript Array.
(async () => {
// previous code
const const pageNumber: 1pageNumber = 1
const const pageSize: 10pageSize = 10
const const paginatedList: Vtt[]paginatedList = const highlightedList: Vtt[]highlightedList
.Array<Vtt>.slice(start?: number, end?: number): Vtt[]Returns a copy of a section of an array.
For both start and end, a negative index can be used to indicate an offset from the end of the array.
For example, -2 refers to the second to last element of the array.slice((const pageNumber: 1pageNumber - 1) * const pageSize: 10pageSize, const pageNumber: 1pageNumber * const pageSize: 10pageSize)
})()The only parameter we need is page number and page size. The page number is a current page that will return and page size is the amount of item will be returned.
ID Remover
The identity added from ID Generator module only useful to build the index for searching purpose. We don’t need it for now and can safely be removed.
(async () => {
// previous code
const const removedIdList: Vtt[]removedIdList = const paginatedList: Vtt[]paginatedList.Array<Vtt>.map<Vtt>(callbackfn: (value: Vtt, index: number, array: Vtt[]) => Vtt, thisArg?: any): Vtt[]Calls a defined callback function on each element of an array, and returns an array that contains the results.map((item: Vttitem) => {
delete item: Vttitem.id?: number | undefinedid
return item: Vttitem
})
})()To remove the identity, we can map the list into a new object and delete the id property.
Formatter
The last module is formatter. We won’t discuss into detail on how this formatter implemented. But the idea of this module is to generate a link for previous, next, first and last page.
(async () => {
// previous code
const const options: FormatterOptionsoptions: type FormatterOptions = {
reqUrl: string;
page: number;
size: number;
dataLength: number;
}
reqUrl: stringreqUrl: 'https://cari-teks-video-api.vercel.app/api',
page: numberpage: const pageNumber: numberpageNumber,
size: numbersize: const pageSize: numberpageSize,
dataLength: numberdataLength: const removedIdList: Vtt[]removedIdList.Array<Vtt>.length: numberGets or sets the length of the array. This is a number one higher than the highest index in the array.length
}
const const response: FormatterReturnTyperesponse: type FormatterReturnType = {
first: string;
last: string;
prev: string;
next: string;
total: number;
page: number;
data: Vtt[];
}
first: stringfirst: function getPaginationUrl(type: PaginationUrlType, options: FormatterOptions): stringgetPaginationUrl(enum PaginationUrlTypePaginationUrlType.function (enum member) PaginationUrlType.FirstFirst, const options: FormatterOptionsoptions),
last: stringlast: function getPaginationUrl(type: PaginationUrlType, options: FormatterOptions): stringgetPaginationUrl(enum PaginationUrlTypePaginationUrlType.function (enum member) PaginationUrlType.LastLast, const options: FormatterOptionsoptions),
prev: stringprev: function getPaginationUrl(type: PaginationUrlType, options: FormatterOptions): stringgetPaginationUrl(enum PaginationUrlTypePaginationUrlType.function (enum member) PaginationUrlType.PrevPrev, const options: FormatterOptionsoptions),
next: stringnext: function getPaginationUrl(type: PaginationUrlType, options: FormatterOptions): stringgetPaginationUrl(enum PaginationUrlTypePaginationUrlType.function (enum member) PaginationUrlType.NextNext, const options: FormatterOptionsoptions),
total: numbertotal: const options: FormatterOptionsoptions.dataLength: numberdataLength,
page: numberpage: const options: FormatterOptionsoptions.page: numberpage,
data: Vtt[]data: const removedIdList: Vtt[]removedIdList
}
})()The getPaginationUrl method receives 2 arguments, the first one is enum. It is for identifying which pagination we currently dealing with. The second argument is the options. Options consist of:
reqUrl, current request URL. If the request to index endpoint, that would be/. And if it is requested to search endpoint, that would be/search.page, current result page, by default it will return the first page.size, how many items should return to the API, by default this would be 10 items.dataLength, how many items the data before paginated.
This article only describes the essential part from the whole source code. If you want to know how the real implementation, please learn more on the GitHub repository, Cari Teks Video API.
Disclaimer
- “This method” refers to all steps or explanations I write on this article.
- “The API” refers to all the API available in https://cari-teks-video-api.vercel.app/api.
- All of this method is pure entirely for research and experimental purpose.
- If YouTube decides to change the behaviour or use some other way, this method probably couldn’t work anymore.
- Since the API is deployed on free version of Vercel, they do have a restriction for function invocation. If suddenly the API inaccessible, it seems it is already hit the limit.
- Because of point number 4 and 5, I can’t guarantee that the API will work forever. But I do regularly check whether it’s still fine or not.
- Please don’t use it on production. I won’t responsible for any side effect usage of the API on production.
- YouTube already have YouTube Data API for Captions to provide the official way of accessing closed captions. Please use that instead of this if you want to use a similar feature on production.
- If you found any bug, please submit an issue on the GitHub repository, Cari Teks Video API.
References
- GitHub: Cari Teks Video API Docs
- GitHub: Search web.dev Live by Sam Dutton
- Google Developers Portal: YouTube Data API for Captions
- StackOverflow: Paginate Javascript Array
- StackOverflow: Regex for YouTube ID